python爬虫selenium
Python爬虫selenium是一种强大的工具,用于自动化测试和网页爬取。它基于JavaScript语言的代码库,最初由Jason Huggins测试工程师开发,旨在减少手工测试量。以下是关于Python爬虫selenium的一些重要内容。 python爬
继续阅读简而言之,Python 爬虫是一段程序,可以自动从网站上获取信息。它可以用于各种目的,例如数据采集、信息监控和自动化任务。
Python 爬虫的工作原理是:
1.使用 HTTP 请求从网站获取网页内容。
2.使用正则表达式或其他工具解析网页内容,提取所需的信息。
3.将提取的信息存储到数据库或文件中。
Python 爬虫可以分为以下几种类型:
1.通用爬虫:通用爬虫是指爬取所有网站的爬虫。通用爬虫通常用于搜索引擎。
2.聚焦爬虫:聚焦爬虫是指爬取特定网站或特定类型网站的爬虫。聚焦爬虫通常用于数据采集或信息监控。
3.深度爬虫:深度爬虫是指能够深入到网页内部进行爬取的爬虫。深度爬虫通常用于爬取链接较深的网页。
Python 爬虫可以用于以下应用:
1.数据采集:Python 爬虫可以用于从互联网上采集数据,例如新闻、商品信息、天气预报等。
2.信息监控:Python 爬虫可以用于监控特定网站或特定类型网站的信息,例如价格变化、新闻动态等。
3.自动化任务:Python 爬虫可以用于自动化一些任务,例如商品比价、订票等。
Python 爬虫的注意事项:
1.遵守网站的爬虫协议:有些网站禁止爬虫,因此在爬取这些网站时,需要遵守网站的爬虫协议。
2.避免被网站封禁:爬取网站时,需要注意不要过度爬取,以免被网站封禁。
3.保护用户隐私:在爬取网站时,需要注意保护用户隐私,避免泄露用户信息。
Python爬虫selenium是一种强大的工具,用于自动化测试和网页爬取。它基于JavaScript语言的代码库,最初由Jason Huggins测试工程师开发,旨在减少手工测试量。以下是关于Python爬虫selenium的一些重要内容。 python爬
继续阅读
Python是一种功能强大的编程语言,提供了许多强大的库和模块,用于处理各种任务。在网络编程方面,Python提供了多个库和模块,其中之一就是requests库,它是一个简单而强大的HTTP请求库,可用于发送各种类型的HTTP请
继续阅读Python爬虫是一种自动化抓取网页数据的技术,它可以帮助我们从互联网上获取各种信息。下面我将以序号的形式,为您解释Python简单爬虫代码的相关内容。 python简单爬虫代码 Python爬虫代码,以获取网页的标题、主题内
继续阅读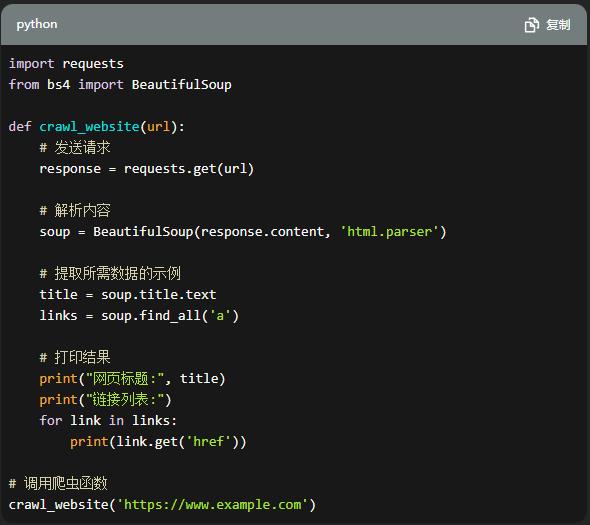
当谈到网络爬虫时,Python 是一个非常受欢迎的语言,因为它具有简单易用的库和强大的功能。网络爬虫是一种自动化程序,用于从互联网上收集数据。它通过模拟浏览器行为发送请求,解析响应并提取所需的信息。下面我将
继续阅读
Python爬虫源码是用于自动化地从网页上获取数据的程序。它可以模拟人的行为,浏览网页、点击链接、提取数据等。 python爬虫原理和类型 Python爬虫的原理是通过发送 HTTP 请求获取网页内容,然后对网页内容进行解析,
继续阅读