python爬虫程序:原理+代码示例
当谈到网络爬虫时,Python 是一个非常受欢迎的语言,因为它具有简单易用的库和强大的功能。网络爬虫是一种自动化程序,用于从互联网上收集数据。它通过模拟浏览器行为发送请求,解析响应并提取所需的信息。下面我将介绍爬虫的原理,并提供一个Python代码示例来说明。
爬虫原理
- 发送请求:爬虫首先发送HTTP请求到目标网站。请求可以是GET请求或POST请求,取决于需要爬取的数据和网站的要求。
- 接收响应:爬虫接收到服务器的响应,包含网页的内容和其他相关信息。响应可以是HTML、JSON、XML等格式。
- 解析内容:爬虫使用解析器(如BeautifulSoup、lxml等)对接收到的内容进行解析,提取出所需的数据,例如链接、文本、图像等。
- 数据处理:爬虫对提取的数据进行处理,可以进行清洗、转换、存储等操作,以便后续分析和使用。
- 遍历页面:爬虫可以通过提取的链接继续访问其他页面,实现深度或广度的数据抓取。
- 反爬机制:为了防止爬虫对网站造成过大的负载或保护敏感信息,网站可能会采取反爬虫措施,如限制访问频率、验证码等。爬虫需要处理这些限制以确保正常运行。
代码示例
以下是一个简单的Python爬虫示例,使用第三方库requests和BeautifulSoup:
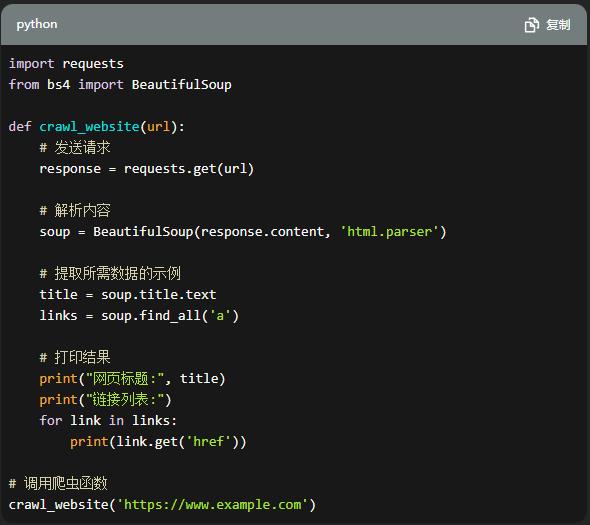
import requests
from bs4 import BeautifulSoup
def crawl_website(url):
# 发送请求
response = requests.get(url)
# 解析内容
soup = BeautifulSoup(response.content, 'html.parser')
# 提取所需数据的示例
title = soup.title.text
links = soup.find_all('a')
# 打印结果
print("网页标题:", title)
print("链接列表:")
for link in links:
print(link.get('href'))
# 调用爬虫函数
crawl_website('https://www.example.com')在这个示例中,我们使用requests库发送HTTP请求,并使用BeautifulSoup解析响应的HTML内容。我们提取了网页的标题和所有链接,并将它们打印出来。
请注意,爬取网站可能需要遵守一些规则和法律,包括但不限于网站的robots.txt文件、使用适当的User-Agent标头、尊重网站的使用条款等。在实际使用爬虫时,请确保遵守相关规定。
应对反爬虫
面对反爬虫措施,爬虫开发者可以采取一些策略来绕过或应对这些防护机制。以下是一些常见的反爬虫措施和对策:
- 限制访问频率:网站可能会限制对同一IP地址的请求频率。为了规避这个限制,可以使用以下策略:
- 添加延迟:在发送请求之间添加固定或随机的延迟,使请求看起来更像是人为操作。
- 使用代理IP:使用代理服务器来隐藏真实的IP地址,以便在一段时间内更换不同的IP地址进行请求。
- 使用多个用户代理:通过使用不同的用户代理标头,模拟不同的浏览器和设备,增加请求的多样性。
- 验证码:有些网站可能会要求用户输入验证码才能继续访问。对策包括:
- 使用第三方验证码识别服务:将验证码图像发送到第三方服务进行识别,并将结果应用于爬虫程序。
- 手动输入验证码:如果验证码不是经常出现,可以手动处理验证码并输入正确的验证码。
- 动态内容:一些网站使用JavaScript或Ajax来动态加载内容,这对爬虫程序是一种挑战。对策包括:
- 使用Headless浏览器:使用无界面浏览器(如Selenium)来模拟实际浏览器的行为,执行JavaScript并获取动态生成的内容。
- 分析API:如果网站有提供API接口,可以直接调用API获取数据,绕过页面中的动态加载。
- 用户登录:某些网站要求用户登录后才能访问内容。对策包括:
- 模拟登录:使用爬虫程序模拟用户登录过程,包括提交登录表单、保存和发送登录凭证等。
- 使用会话维持登录状态:在登录后,保持会话状态并在后续请求中发送相应的会话标识。
- IP封锁:如果网站封锁了某些IP地址范围,可以考虑以下对策:
- 使用代理IP:使用代理服务器来隐藏真实的IP地址,以便绕过封锁。
- 使用Tor网络:Tor网络可以帮助匿名浏览和爬取网站,通过路由流量进行匿名代理。
无论采取何种对策,都应该遵守网站的使用条款和法律法规,并尊重网站的资源和隐私。此外,反爬虫措施可能会随时发生变化,因此爬虫开发者需要密切关注目标网站的更新,并对爬虫程序进行相应的调整和优化。
这只是一个简单的示例,爬虫的功能和复杂性可以根据需求进行扩展和调整。希望这个示例能帮助你理解爬虫的基本原理和使用Python实现的方法。