python爬取网页内容
Python是一种功能强大的编程语言,可以用于各种任务,包括网页内容的抓取。在本文中,我们将探讨使用Python进行网页内容的爬取,并提供一些相关资源和示例代码。
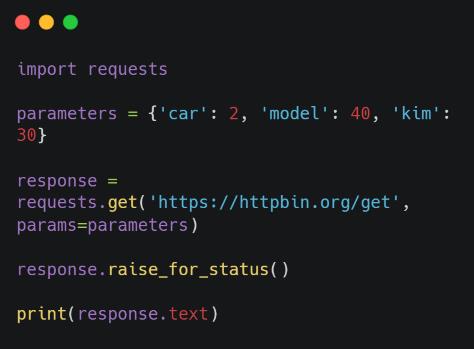
使用requests库进行网页内容的抓取
在Python中,有许多库可以用于网页内容的抓取,其中最常用的是requests库。这是一个简单易用的HTTP库,可以发送HTTP/1.1请求,实现网页内容的抓取。
以下是使用requests库进行网页内容抓取的基本步骤:
- 导入requests库:首先,我们需要在Python脚本中导入requests库,以便可以使用其中的函数和方法。
- 发送HTTP请求:使用requests库的get()方法,指定待抓取网页的URL,并发送HTTP请求。
- 获取网页内容:使用response对象的content属性,可以获取到网页的原始内容。
- 解析网页内容:将获取到的网页内容进行解析,提取所需的信息。这可以使用Python中的各种解析库,如BeautifulSoup。
- 存储网页数据:将抓取到的网页数据进行存储,可以选择保存为文本文件、数据库或其他形式。
使用BeautifulSoup进行网页内容的解析
BeautifulSoup是Python中一个用于解析HTML和XML的库,可以帮助我们从网页内容中提取出所需的信息。
以下是使用BeautifulSoup进行网页内容解析的基本步骤:
- 导入BeautifulSoup库:首先,我们需要在Python脚本中导入BeautifulSoup库。
- 创建BeautifulSoup对象:使用BeautifulSoup库的构造函数,传入待解析的网页内容和解析器类型,创建一个BeautifulSoup对象。
- 查找网页元素:使用BeautifulSoup对象的find()或find_all()方法,可以根据标签名、类名、属性等条件查找网页中的元素。
- 提取元素信息:对于找到的元素,可以使用其属性和方法提取所需的信息。例如,使用元素的text属性可以获取到其文本内容。
示例代码
下面是一个使用requests和BeautifulSoup库进行网页内容抓取和解析的示例代码:
import requests
from bs4 import BeautifulSoup
# 发送HTTP请求并获取网页内容
url = 'http://www.example.com'
response = requests.get(url)
content = response.content
# 创建BeautifulSoup对象进行网页内容解析
soup = BeautifulSoup(content, 'html.parser')
# 查找网页元素并提取信息
title = soup.find('title').text
print(title)
以上代码演示了如何使用requests库发送HTTP请求并获取网页内容,然后使用BeautifulSoup库解析网页内容,并提取其中的标题信息。
希望本文能够帮助您了解如何使用Python进行网页内容的爬取。无论是学习爬虫还是实际项目,这些技术都会对您有所帮助。祝您在Python爬取网页内容的旅程中取得成功!