python onehot编码
One-hot 编码,又称一位有效编码,是一种将离散型数据转换为连续型数据的编码方式。它将每个离散值映射到一个长度为该值取值总数的二进制向量,其中只有一个值为 1,其余值均为 0。
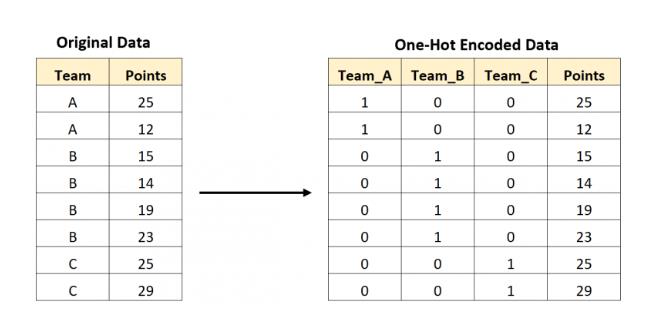
在 Python 中,可以使用 sklearn.preprocessing.OneHotEncoder() 类来进行 One-hot 编码。
import numpy as np
from sklearn.preprocessing import OneHotEncoder
# 创建数据
data = np.array([1, 2, 3, 4])
# 创建 One-hot 编码器
encoder = OneHotEncoder(categories='auto')
# 进行 One-hot 编码
encoded_data = encoder.fit_transform(data).toarray()
print(encoded_data)输出:
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]
[0. 0. 0.]]
在上述示例中,我们创建了一个包含 4 个元素的整数数组 data。然后,我们创建了一个 One-hot 编码器,指定 categories='auto' 表示自动为数据的类别数目选择合适的值。最后,我们使用 fit_transform() 方法将数据进行 One-hot 编码,并将结果保存在 encoded_data 中。
One-hot 编码通常用于机器学习中,以便将离散型数据转换为连续型数据,以便于机器学习模型进行处理。
Python中的One-hot编码是将类别变量转换为二进制向量的常用技术。它在机器学习和深度学习任务中广泛应用,可以有效处理具有类别特征的数据。
要在Python中实现One-hot编码,我们可以使用scikit-learn库中的OneHotEncoder模块。首先,我们需要导入所需的库和数据集。我们可以使用pandas库的read_csv函数读取CSV文件,并使用head函数显示前几行数据,以便查看数据的结构。
接下来,我们使用OneHotEncoder模块对类别变量进行编码。首先,我们需要将类别变量提取出来,并将其转换为数值形式。我们可以使用pandas库的get_dummies函数将类别变量转换为虚拟变量,也就是包含0和1的二进制向量。
然后,我们可以使用OneHotEncoder模块对虚拟变量进行编码。我们需要创建一个OneHotEncoder对象,并使用fit_transform函数对数据进行编码。编码后的结果将是一个稀疏矩阵,每一列对应一个类别变量的取值。
最后,我们可以将编码后的结果转换为pandas的DataFrame对象,以便更容易查看和分析数据。我们可以使用pandas的DataFrame函数将编码后的稀疏矩阵转换为DataFrame,并指定列名。
通过以上步骤,我们可以将类别变量进行One-hot编码,并得到编码后的结果。这样,我们就可以在机器学习或深度学习模型中使用这些编码后的特征进行训练和预测。
总结起来,Python中实现类别变量的One-hot编码的步骤如下:
1. 导入所需的库和数据集。
2. 使用pandas库的read_csv函数读取CSV文件,并使用head函数显示前几行数据。
3. 使用pandas库的get_dummies函数将类别变量转换为虚拟变量。
4. 创建OneHotEncoder对象,并使用fit_transform函数对数据进行编码。
5. 将编码后的结果转换为pandas的DataFrame对象,以便更容易查看和分析数据。
通过这些步骤,我们可以在Python中轻松实现类别变量的One-hot编码,并为后续的机器学习和深度学习任务做好准备。希望以上内容对你有所帮助!